
Complex Engineering Systems







Zhiwen Chen , ... Zhiyong Chen
, ... Zhiyong Chen
, ... Zhiyong Chen
Views: Downloads:
Views: Downloads:
Views: Downloads:
Views: Downloads:
Shurendher Kumar Sampathkumar, ... Donghoon Kim
Views: Downloads:
Anoop Sathyan, ... Kelly Cohen
, ... Kelly Cohen
Views: Downloads:
Alessandro Formenti, ... Loris Roveda
Views: Downloads:
Views: Downloads:









Data
200
Authors
275
Reviewers
2021
Published Since
67,403
Article Views
24,784
Article Downloads
For Reviewers
For Readers
Add your e-mail address to receive forthcoming Issues of this journal:
Themed Collections
Related Journals

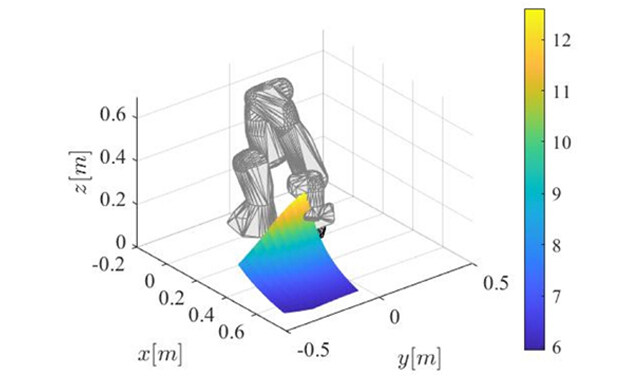
Alessandro Formenti, ... Loris Roveda
Open Access | Research Article | 18 Jul 2022
Views: | Downloads:
Related Journals
Data
200
Authors
275
Reviewers
2021
Published Since
67,403
Article Views
24,784
Article Downloads



